Contributions
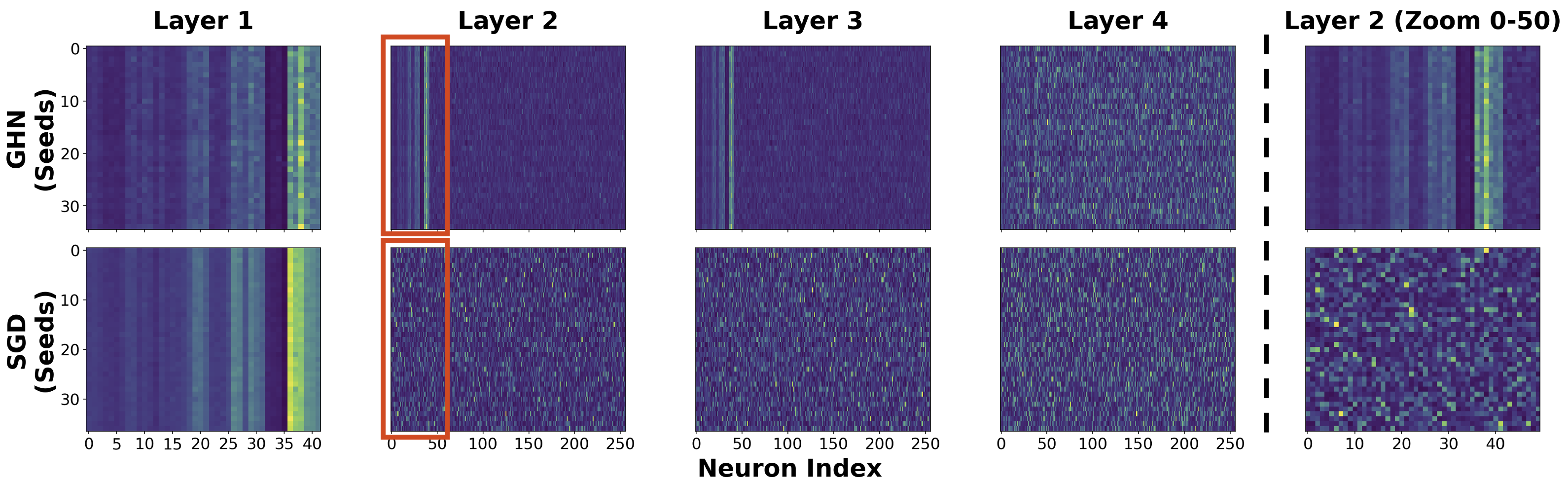
- Structurally aligned weight spaces. We show that Graph HyperNetworks with a CNN decoder collapse permutation symmetry into a structurally aligned weight space — consistent and spatially correlated across networks — so raw weights can be tokenized into patches.
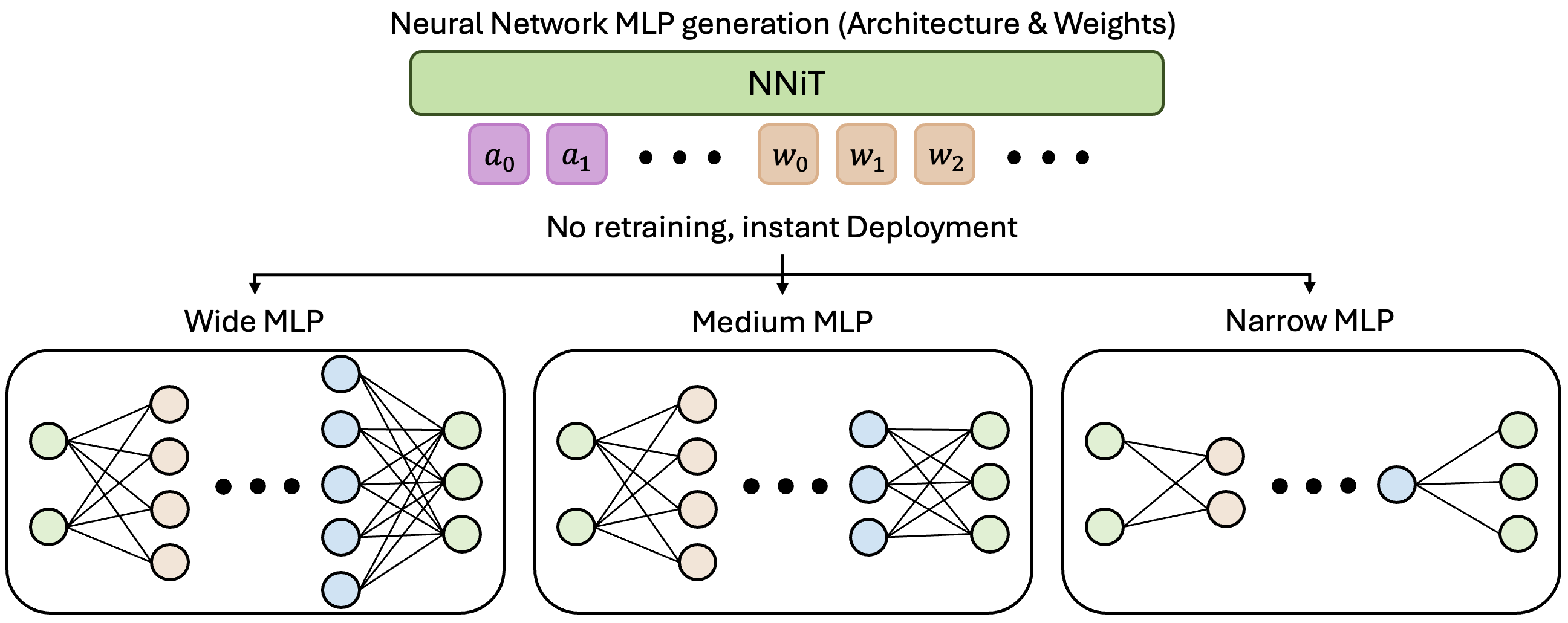
- Patch tokenization for weights. Representing weights as patches makes generation width-agnostic: synthesizing a wider layer just adds patches, enabling zero-shot synthesis for unseen architecture topologies.
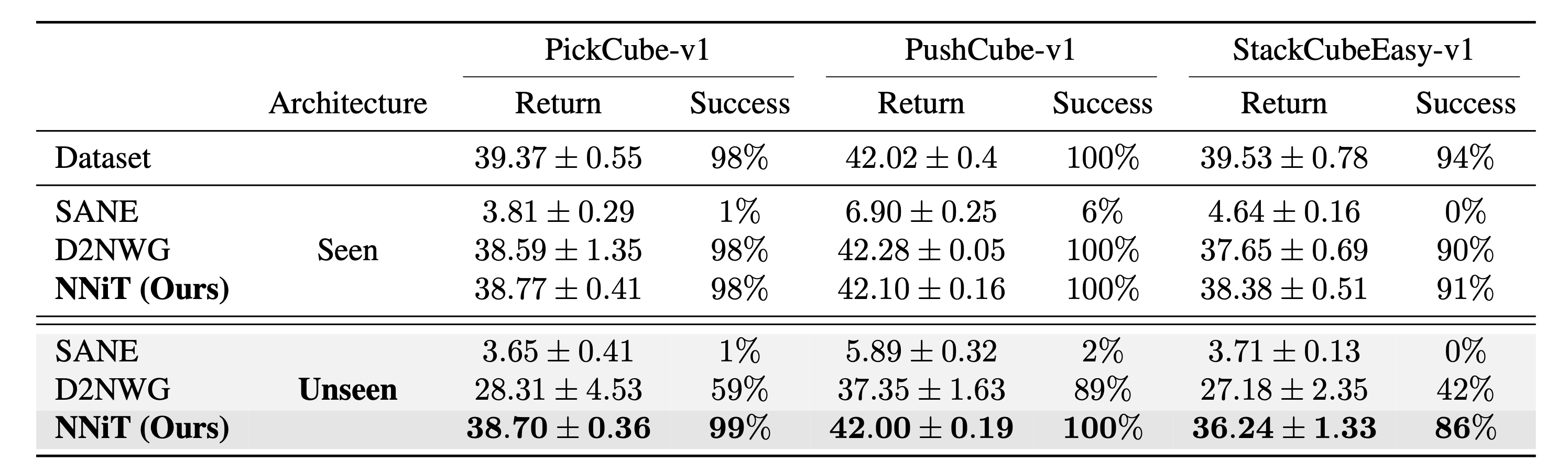
- NNiT. A multimodal diffusion transformer that jointly models discrete architecture tokens and continuous weight patches — supporting both conditional synthesis p(w | a) and joint generation p(a, w).